Every AI failure I have ever witnessed, and what eventually led me to build the Context Architecture Method, traces back to the same root cause.
Not a bad model. Not a weak prompt. Not the wrong tool.
Missing context.
I know this because I spent hundreds of hours building what I called the Awesome OS. It was a zero-employee, AI-first business that runs entirely on agents and automation. I set up department agents for content, research, finance, operations, and engineering. I connected them to knowledge bases, wired up automation pipelines, and tried to run an entire company through tokens instead of headcount.
For a long time, it was a disaster.
The agents produced generic output. The quality swung wildly between sessions. I kept rewriting prompts, trying better models, adding more instructions. Nothing worked until the day I stopped asking “how do I phrase this better?” and started asking “what does this agent actually need to know?”
That shift changed everything. It is the same shift that separates businesses extracting real value from AI from the ones cycling through tools and wondering why none of them stick.
This post is the full framework I built from that experience: The Context Architecture Method™.
It is the most important thing I have learned about AI in business. Not which model to use. Not how to write a prompt. How to architect context as the intelligence layer between human intent and AI execution.
Why “context engineering” is replacing prompt engineering
In June 2025, Shopify CEO Tobi Lütke wrote something that crystallised what production AI teams had been discovering through painful experience. His exact words:
I really like the term ‘context engineering’ over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
Tobi Lütke, CEO of Shopify
Within hours, Andrej Karpathy had amplified the point. Karpathy was the former Director of AI at Tesla and former researcher at OpenAI. His words:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.
Andrej Karpathy
These are not casual observations. They are public acknowledgements of a discipline that had been quietly maturing in engineering teams for years.
Prompt engineering asks: How do I phrase this request?
Context engineering asks: What does this system need to know, believe, remember, and access in order to succeed?
One is a writing skill. The other is an architecture skill. The gap between them is where most AI initiatives go to die.
The model is not the variable
Here is the insight that reshapes how you think about AI: a model is only as intelligent as the context you give it.
The same model that gives you generic, hallucination-prone nonsense with a vague prompt will produce expert-level, company-specific, genuinely useful work when given rich, structured, well-engineered context.
This matters strategically. Every business now has access to the same frontier models. OpenAI, Anthropic, Google, Meta. The capability gap between providers is closing fast. A 2025 study from the University of Washington tested over 70 language models and found something striking: despite being built by different companies on different architectures, they converge on almost identical outputs for open-ended questions. The researchers called it the “Artificial Hivemind” effect.
Ask any of these models to write a metaphor about time, and most will reach for “time is a river.” Ask for creative ideas, and they surface the same ideas. Ask for strategic advice, and they offer the same frameworks.
The outputs are competent, fluent, and deeply uniform.

Without distinctive context, every business using AI produces identical output. Your competitors are writing the same blog posts, the same emails, the same proposals. Not because they use the same tools. Because they feed those tools the same absence of context.
This is the deepest argument for context engineering. It is not an optimisation. It is the entire competitive game.
The science behind why context matters so much
Your AI has working memory, just like you do
The most illuminating lens for understanding context engineering comes not from computer science, but from cognitive psychology.
Baddeley’s model of working memory describes the mental workspace where we hold and manipulate information in the moment. Research from George Miller’s 1956 paper established that humans can hold roughly seven items in working memory simultaneously. Modern research has revised this down to around four chunks.
An LLM’s context window functions as its working memory. It is the total amount of information the model can hold in mind while generating a response. Just like human working memory, it has hard limits and performance characteristics that degrade under load.
John Sweller’s Cognitive Load Theory gives us a practical framework here. Sweller identified three types of cognitive load.
Intrinsic load is the inherent complexity of the task. A legal contract review is genuinely harder than a social post. You cannot reduce this without simplifying the task itself.
Extraneous load is unnecessary information or poorly structured content that wastes working memory capacity without contributing to understanding. This is the enemy.
Germane load is the productive cognitive effort spent building understanding and reasoning. This is the goal.
The transfer to AI is direct. Extraneous context load is irrelevant, redundant, and poorly structured information dumped into the context window. It is the number one cause of poor AI performance, and it is entirely preventable.
The goal of context engineering is not to maximise the amount of context. It is to maximise the signal-to-noise ratio within the available context window. More is not better. Better is better.
The lost-in-the-middle effect
In 2024, a landmark paper by Liu et al. in the Transactions of the Association for Computational Linguistics demonstrated something every context engineer needs to understand: LLMs exhibit a U-shaped attention curve.
Models perform best when relevant information appears at the very beginning or very end of the context window. They perform worst when it appears in the middle.
This mirrors the serial position effect in human memory. We remember the beginning and end of a list better than the middle. For AI systems, a follow-up study from MIT and Google confirmed the mechanism: the model’s architecture literally pays less attention to middle-positioned content.
The practical implication is clear. Put your most critical context at the top and bottom of the context window. Foundation-level instructions and identity belong at the top. The specific task and desired output belong at the bottom. Supporting documents sit in the middle, structured with clear headings and markers so the model can attend to them.
Context as cognitive scaffolding
Vygotsky’s concept of the Zone of Proximal Development describes the gap between what a learner can do independently and what they can do with appropriate support. The support structure that bridges this gap is called scaffolding.
AI systems have a zone of proximal development too. A foundation model, alone, handles general tasks reasonably well. But there is a vast space of company-specific, domain-specific, context-dependent tasks it cannot do without support. Context engineering is the scaffolding that closes this gap.
Jerome Bruner identified three key properties of effective scaffolding: it reduces the degrees of freedom in the task, it maintains the direction of the work, and it marks critical features the learner might miss. These are precisely the properties of effective context.
The three layers of the Context Architecture Method
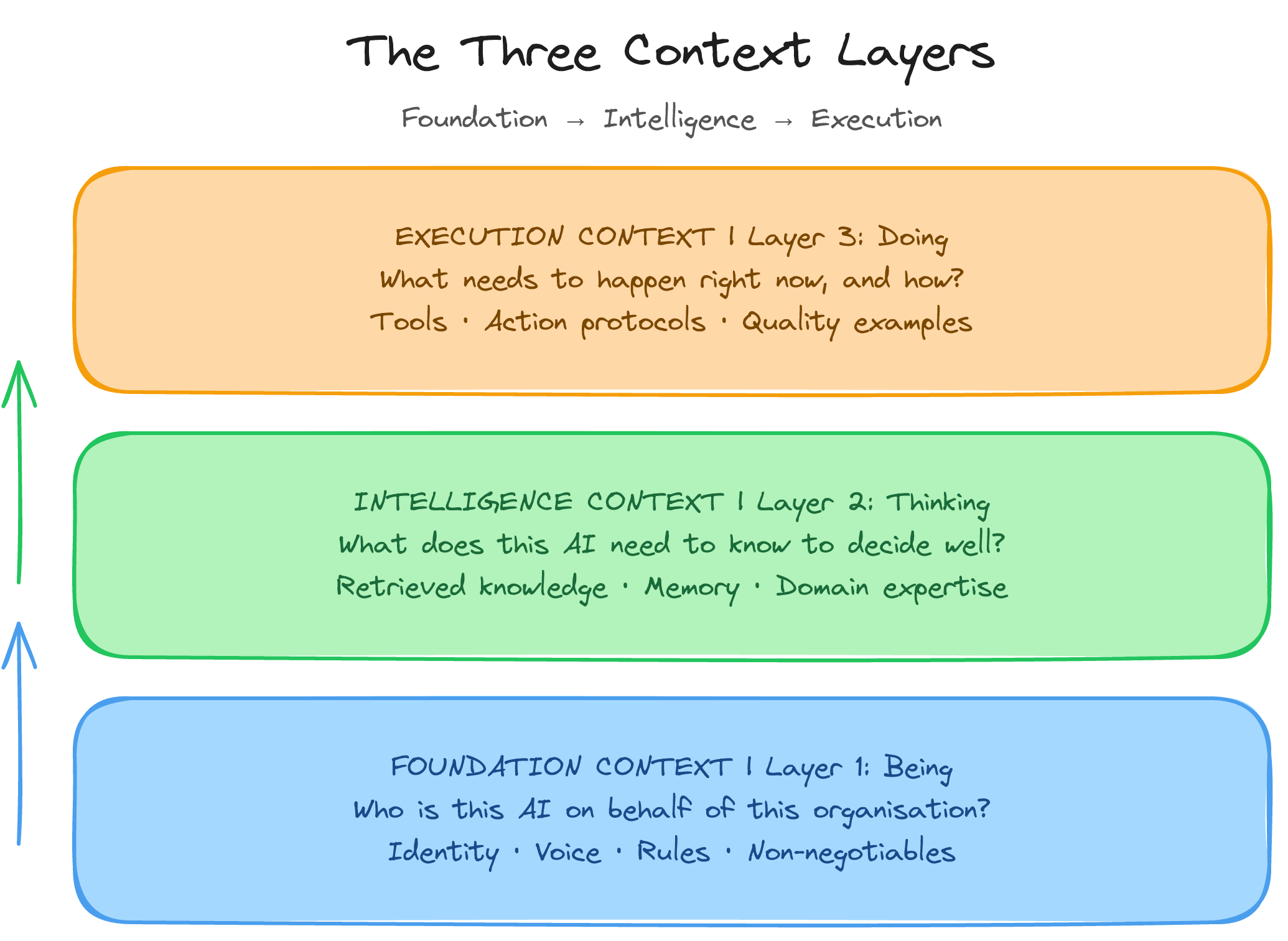
The Context Architecture Method is built on three layers that describe what your context architecture must contain.
Layer 1: Foundation Context
Foundation Context answers the question: who is this AI when it operates on behalf of our organisation?
This is the most overlooked and most consequential layer. It defines organisational identity: mission, values as genuine decision-making constraints, brand voice, cultural norms, and the things you never do. It defines operational identity: the AI’s role, what it can decide independently, and what needs human approval. And it defines relational identity: how the AI should relate to different stakeholders, and what tone it takes with different audiences.
Most businesses skip this layer entirely. They deploy AI tools with no identity definition, no voice guidance, no ethical boundaries, and then wonder why the outputs feel generic or occasionally wildly off-brand.
The implementation artefact for this layer is what I call the Context Constitution™. It is a living document of 1,000 to 1,500 words that captures all of the above. When I built my own, I included specific sentence patterns that represent my voice, words I never use, examples of writing I consider excellent, examples I consider unacceptable, and decision-making principles for edge cases.
It took a few hours to write. It is the single most valuable asset in my entire AI infrastructure.
Layer 2: Intelligence Context
Intelligence Context answers: what does this AI need to know to make good decisions?
This is where most of the technical weight sits. It includes institutional knowledge: your products, services, pricing, customer segments, industry context. It includes domain expertise: regulations, technical documentation, decision frameworks. And it includes historical memory: conversation histories, previous decisions, customer relationship context.
Most critically, it includes the retrieval systems that make this knowledge accessible at inference time. RAG (Retrieval-Augmented Generation) pipelines, vector databases, search systems, and memory that persists across conversations.
The key challenge is not having the information. Most businesses have enormous stores of knowledge. The challenge is making that knowledge accessible and retrievable at the moment the AI needs it.
When I built a semantic retrieval layer over my personal knowledge base, hundreds of notes on frameworks, research, and business strategy, the same AI assistant that had been giving me generic advice started drawing on my own thinking and frameworks. The knowledge existed before. The architecture to surface it at the right moment did not.
Layer 3: Execution Context
Execution Context answers: what specifically needs to happen, and how should it happen?
This layer is closest to traditional prompt engineering, but it operates within the container established by Foundation and Intelligence. It includes task definition: the specific objective, output format, length, constraints. Tool access: what APIs, databases, or systems the AI can call. Action protocols: step-by-step instructions for complex workflows and decision trees for branching scenarios. And quality standards: examples of good outputs, anti-examples, and review checklists.
Most context engineering approaches focus exclusively on this layer. They skip Foundation and Intelligence entirely. This is why so many AI implementations feel hollow and inconsistent, despite using the same frontier models that produce remarkable results elsewhere.
The five phases of the Context Architecture Method
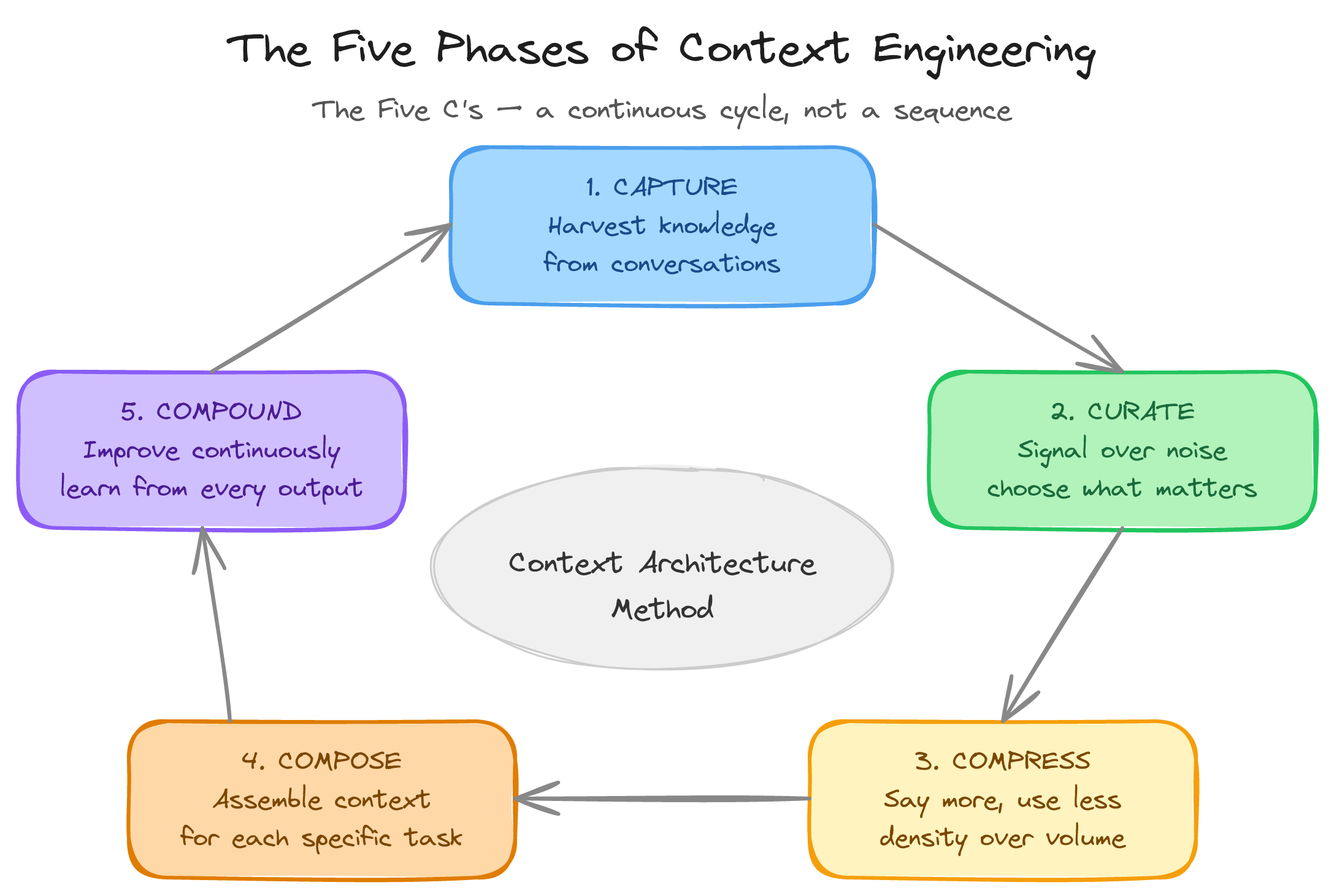
The three layers describe what your context architecture contains. The five phases describe how to build and improve it over time. They form a cycle because context architecture is never done. It is a living system.
Phase 1: Capture
Capture is the process of identifying and extracting the knowledge that currently exists inside your organisation. This knowledge is usually trapped in people’s heads, scattered across documents, or embedded in habitual behaviours nobody has ever articulated.
The Capture Audit asks: what does a new employee need to know in their first 90 days? What questions do customers ask most frequently, and what are the correct answers? What decisions get made repeatedly, and what information informs those decisions? Where is institutional knowledge most concentrated?
Practical methods include structured interviews with subject matter experts, process documentation sessions, customer interaction analysis mining support tickets and sales calls, systematic document harvesting, and decision journaling where leaders log their reasoning for 30 days.
Phase 2: Curate
Curate is where raw knowledge becomes useful context. Not everything captured in Phase 1 belongs in the context window. Curate is the discipline of deciding what goes in, what stays out, and what gets transformed.
The guiding principle is signal-to-noise. Every token either contributes to the AI’s ability to complete the task (signal) or detracts from it (noise).
Information falls into three buckets. Always-On Context is what every interaction needs: identity, voice, core rules. Retrieved Context is what specific tasks need, pulled dynamically from your knowledge base. Ephemeral Context is specific to a single interaction, appearing naturally and disappearing when the interaction ends.
The most common curation mistake is treating everything as Always-On. Early in building the Awesome OS, I crammed every possible piece of context into system prompts. The token overhead was enormous. The solution was not less context. It was smarter context: a lean Always-On layer with dynamic retrieval pulling in whatever each specific task required.
Phase 3: Compress
Compress is the art of saying more with fewer tokens.
Semantic compression rewrites information to convey the same meaning in fewer words. A 500-word policy document often compresses to a 50-word rule without losing decision-relevant information. Structural compression uses formatted rules instead of prose: a four-paragraph refund policy becomes a simple decision table. Example compression uses a single well-chosen input/output example to replace three paragraphs of instruction.
The Context Density Score measures the ratio of decision-relevant tokens to total tokens. Most businesses operate at 0.15 to 0.25 before intentional context engineering, meaning 75 to 85% of what they feed their AI systems is wasted bandwidth. Improving this ratio has direct financial implications: the same or better output quality for fewer tokens.
Phase 4: Compose
Compose is the dynamic assembly of the right context for the right task at the right moment.
The Context Assembly Pattern™ positions context in four locations:
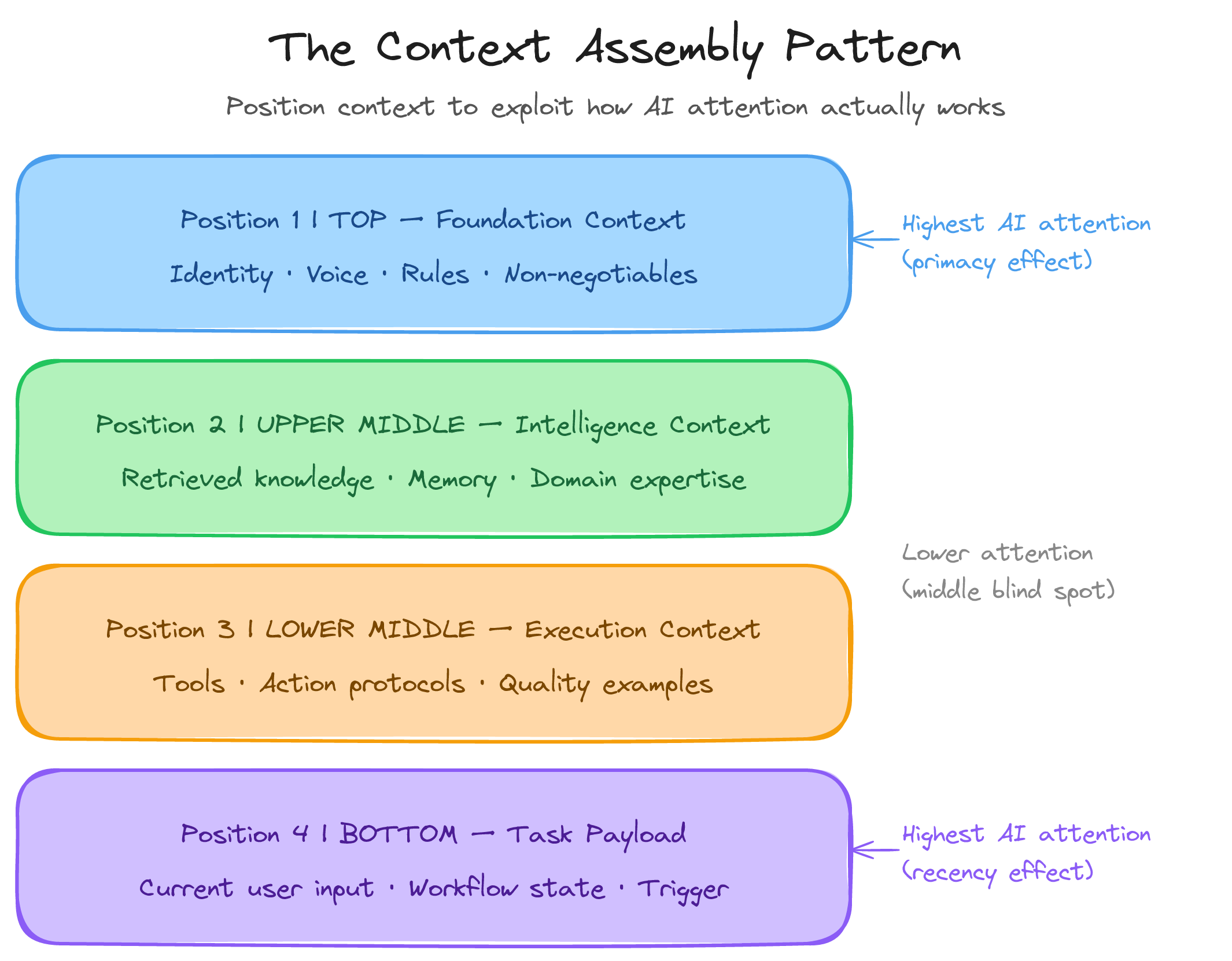
Top (Position 1): Foundation Context. Identity, voice, rules, boundaries. This sits at the primacy position where the model pays most attention.
Upper-Middle (Position 2): Intelligence Context. Retrieved documents, memory, domain knowledge.
Lower-Middle (Position 3): Execution Context. Tools, action protocols, quality examples.
Bottom (Position 4): Task Payload. The current user input, state, or trigger. This sits at the recency position where the model pays most attention.
To make the difference concrete, consider drafting a client proposal. With no context, the prompt is “write a proposal for a retail client who needs help with inventory management.” The AI has no information about your methodology, your voice, your relevant case studies, or your standards. The output will be generic. You will spend 45 to 60 minutes rewriting it.
With the Context Assembly Pattern, Position 1 carries your methodology and voice guide (~800 tokens). Position 2 carries a relevant case study and the client’s discovery notes (~1,200 tokens). Position 3 carries the output format and quality constraints (~400 tokens). Position 4 carries the specific task.
Total: around 2,400 tokens. The result is a proposal that reads as though a senior person who knows the firm, the methodology, the client, and the industry wrote it. The review takes 10 to 15 minutes. This is the One-Shot Principle in action.

Phase 5: Compound
Compound transforms context engineering from a one-time setup into a compounding competitive advantage. Small, consistent improvements in context quality produce exponentially better AI performance over time.
The compounding mechanisms include interaction mining, where successful interactions become new few-shot examples and failed interactions improve decision trees. They also include entropy countermeasures, where freshness scoring and scheduled reviews ensure the Intelligence Layer stays current. And performance analytics, tracking one-shot success rate, human correction rate, and task completion time.
The five context archetypes: where do you sit?
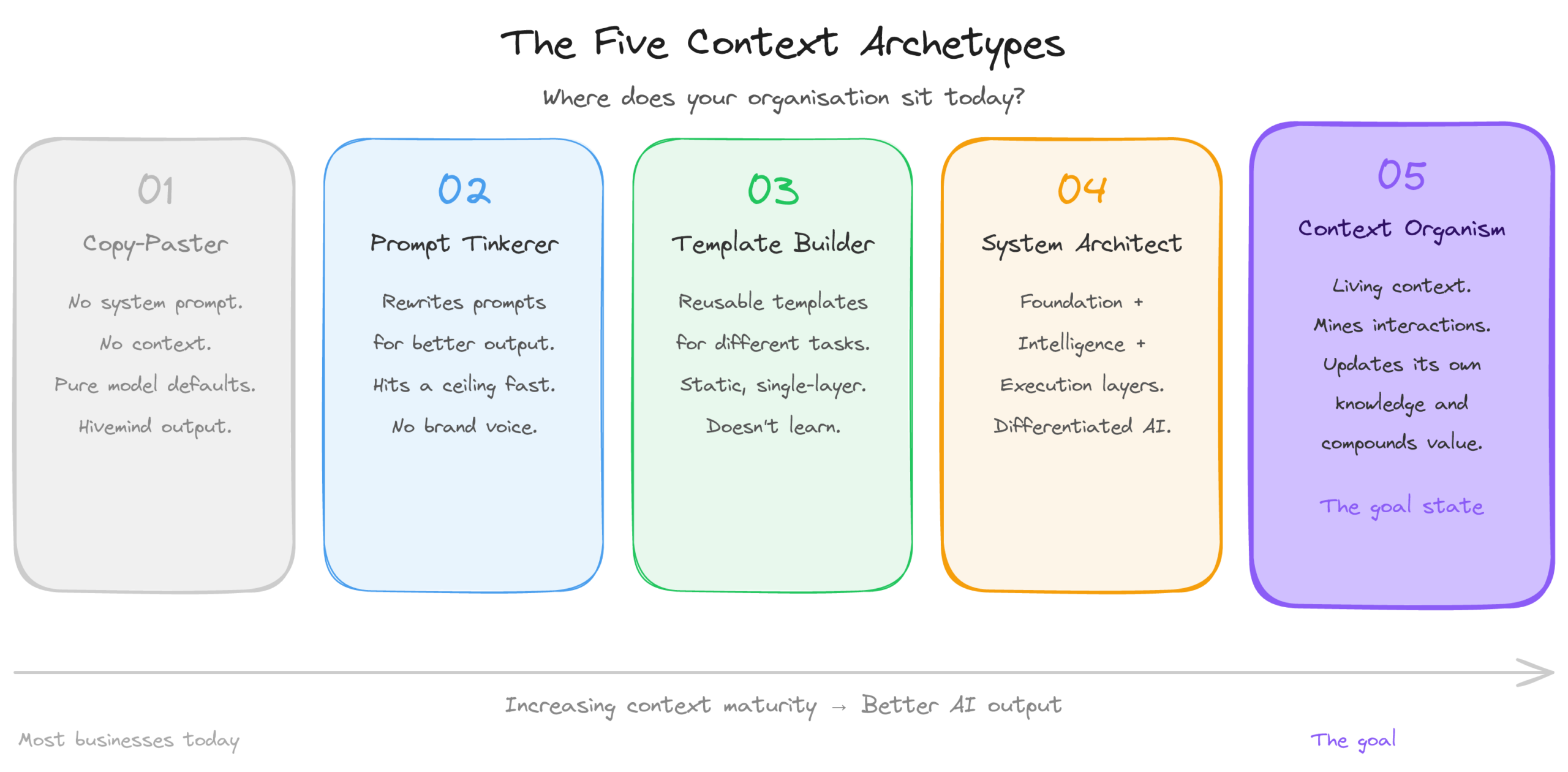
Working with founders and business leaders across multiple sectors, I have identified five distinct archetypes that describe how organisations relate to AI context.
Archetype 1: The Copy-Paster. Opens ChatGPT, types a request with no system instructions, no background, no constraints, and accepts whatever the model produces. The output is pure model defaults. Pure Artificial Hivemind. Indistinguishable from every competitor doing the same thing.
Archetype 2: The Prompt Tinkerer. Has discovered that how you ask matters. Spends significant time refining prompts, trying different phrasings, collecting saved prompts for recurring tasks. This is a genuine improvement, but it hits a ceiling fast. No amount of careful phrasing gives the model institutional knowledge, brand voice, or customer context.
Archetype 3: The Template Builder. Has systematised their prompting. Reusable templates for different task types, perhaps with custom instructions. This is where most “advanced” AI users sit today. It is a meaningful step, but it remains static and single-layer. The templates do not learn, do not retrieve relevant knowledge dynamically, and do not adapt.
Archetype 4: The System Architect. Has built a structured context architecture across multiple layers: a defined Foundation Context, an Intelligence Layer connected to retrieval systems, and dynamic Execution templates composed based on the situation. This is the threshold archetype where AI output becomes genuinely differentiated and consistently high-quality.
Archetype 5: The Context Organism. Has a living, self-improving context architecture that monitors its own performance, identifies gaps, refreshes stale knowledge, and evolves over time. The human role shifts from operating the AI to stewarding the context ecosystem. Very few organisations have reached this archetype today.
Most businesses operate between Archetype 1 and 2. Moving to Archetype 3 or 4 produces a 3 to 5x improvement in AI output quality and a corresponding reduction in human oversight requirements.
The seven context sins (and how to fix them)
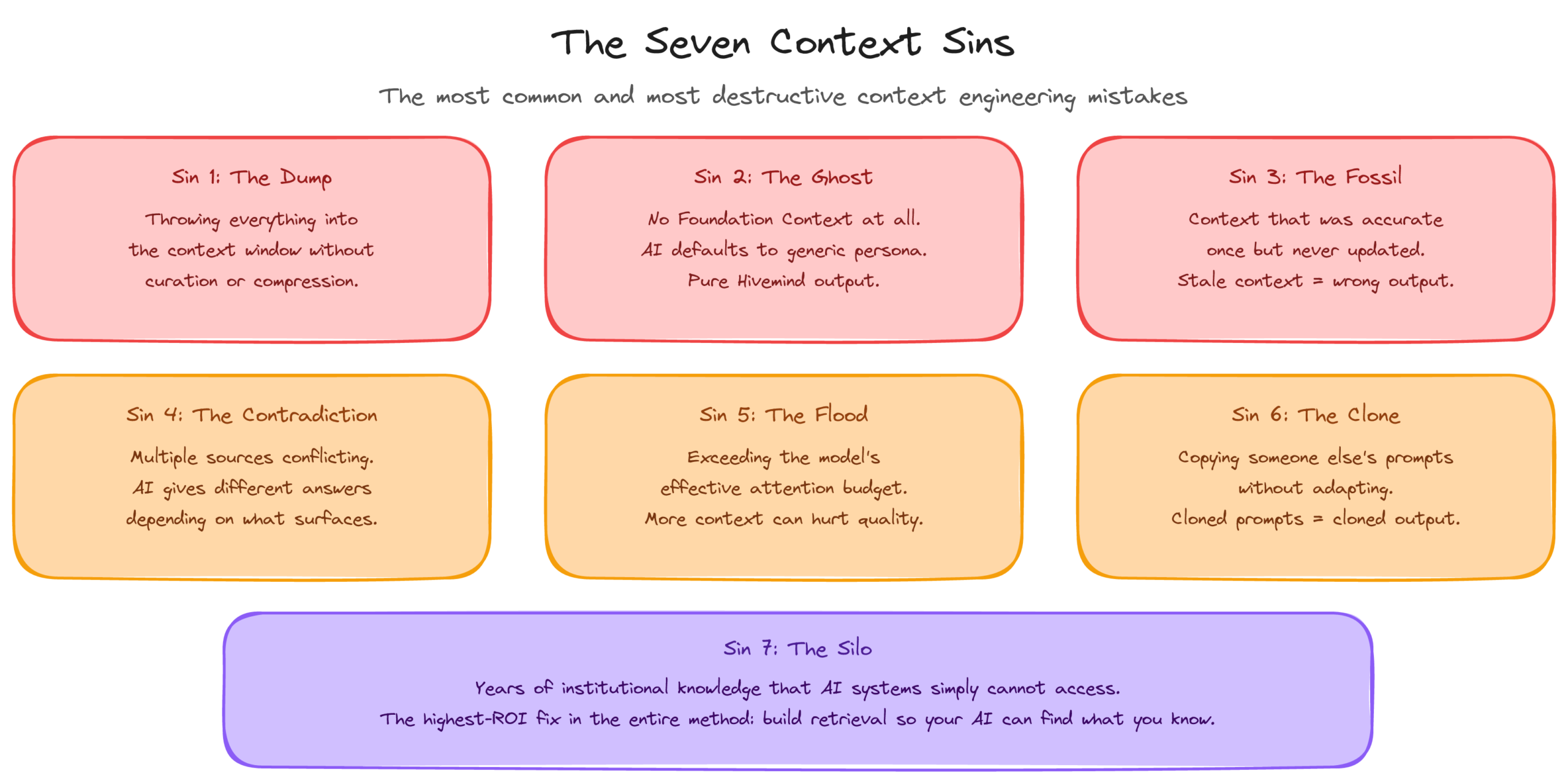
Understanding what not to do is as important as understanding what to do. Here are the seven most common and most destructive context mistakes.
The structural sins: how bad foundations fail you
Sin 1: The Dump. Throwing everything into the context window without curation or compression. More context is not better context. Extraneous load overwhelms germane load and the model drowns in noise. Fix it with the Curate and Compress phases.
Sin 2: The Ghost. Operating with no Foundation Context at all. The AI defaults to its generic training persona, which sounds like every other AI output in the world. An agency using AI to draft social posts for five different clients, with no brand voice definition for any of them, will produce five posts that sound identical. Fix it with the Foundation Layer.
Sin 3: The Fossil. Context that was accurate once but has not been updated. Stale context is uniquely dangerous because the AI trusts it completely. It has no way to assess the freshness of information in its context window. Fix it with the Compound phase and Freshness Scoring.
The operational sins: how good foundations break in practice
Sin 4: The Contradiction. Multiple context sources that conflict with each other. A company with different returns policies on the website, in the training manual, and in the FAQ. The AI gives different answers depending on which document surfaces. Fix it with the Curate phase’s Conflict Resolution Protocol.
Sin 5: The Flood. Exceeding the model’s effective attention budget. Even with a 200,000-token context window, performance degrades well before that limit. Loading every tool definition and every knowledge base simultaneously buries the model before it receives a task. Fix it with the Compose phase by loading only what is relevant to the current task.
Sin 6: The Clone. Copying someone else’s prompts or context structures without adapting them to your organisation’s reality. Cloned prompts produce cloned output. Context engineering is fundamentally about organisational specificity. Fix it with the Capture phase. There is no shortcut.
Sin 7: The Silo. Context exists within the organisation but AI systems cannot access it. A consultancy with twelve years of project documentation, client presentations, and hard-won expertise, none of it in a format AI can use. Their AI operates as though the company was founded yesterday. Fix it with the Capture and Curate phases, specifically the knowledge harvesting and retrieval architecture work. This is consistently the highest-ROI investment in the entire method.
Context Entropy: the decay problem nobody talks about
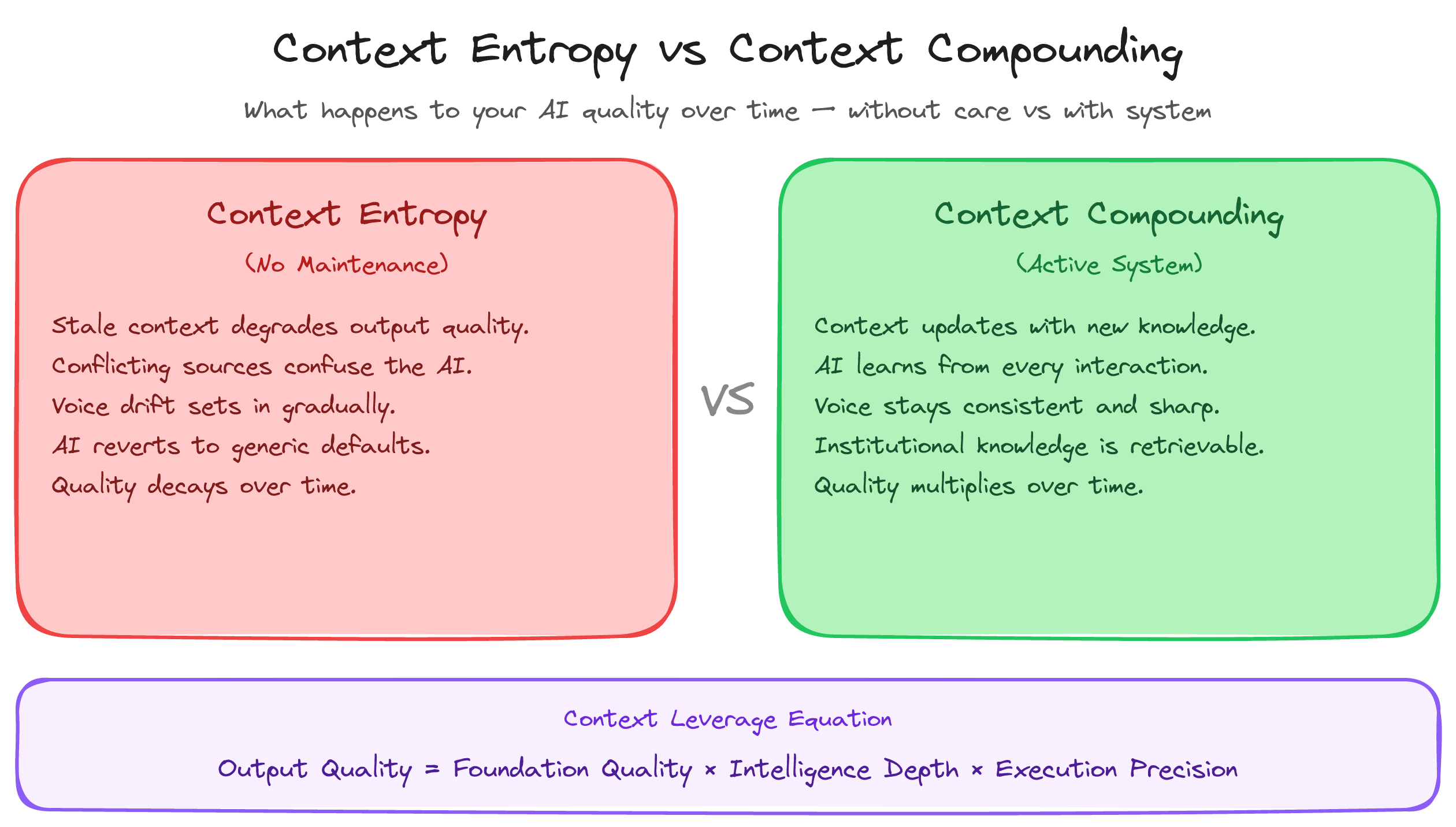
There is a concept missing from virtually every discussion of context engineering: Context Entropy™, the inevitable decay of context quality over time.
A perfectly curated, well-structured context architecture will degrade without continuous maintenance. Prices change. Policies update. Team members leave and take institutional knowledge with them. Products get discontinued. Markets shift. The world moves, and the context stays frozen.
The rate of entropy varies by content type. High-velocity decay affects pricing, inventory, staffing, and current promotions. This information can become stale within days. Medium-velocity decay affects processes, brand positioning, competitive context, and customer personas. These change quarterly. Low-velocity decay affects organisational values, core methodology, and industry fundamentals. These change rarely but need reviewing annually.
Context Entropy is not a failure. It is a natural law. You cannot prevent it. You can only manage it.
Freshness Scoring is a practical mechanism. Every context element carries metadata indicating when it was last verified and when review is due. Elements past their review date get flagged. Elements more than two review cycles overdue get quarantined, removed from active retrieval until verified.
The Context Architecture Method business case: what does it actually deliver?
Context engineering creates measurable, calculable returns. The formula I use is:
Value = (Quality × Speed × Consistency) / (Oversight × Cost)
Quality, Speed, and Consistency are multiplicative. They compound together. Oversight and Cost sit in the denominator, so any reduction amplifies the total value.
At the solo founder level, a content strategist who builds Context Constitutions for each client and connects a small knowledge base of best-performing work can cut rework from 30 to 40 minutes per piece down to 8 minutes. One-shot success rate rises from 20% to 70%. That translates to roughly $46,000 a year saved, and more importantly, the capacity to take on two additional clients without hiring.
At boutique agency scale (12 people, $2M revenue), with per-client Context Constitutions and role-specific execution templates, the annual saving runs to $150,000 or more, with a consistency improvement that reduces client revision requests significantly.
At mid-market scale (100 people, $25M revenue), deploying a centralised Foundation Context with departmental Intelligence Layers, the annual delta approaches $450,000, plus measurable improvements in NPS, reduced escalations, and faster sales cycle.
The pattern holds at every scale: the majority of the cost before context engineering is human oversight, not technology. AI tools are cheap. The human time required to compensate for AI’s lack of context is not. Context engineering does not reduce the cost of AI. It reduces the cost of humans fixing AI output.
The model portability principle: build for the long game
A context architecture must be model-agnostic. This is not a nice-to-have. It is a strategic imperative.
The AI model market moves fast. Today’s frontier model is tomorrow’s baseline. Providers change pricing, deprecate models, and shift capabilities. A business whose context architecture only works with one specific model from one specific provider has built a dependency, not a moat.
The Context Architecture Method is deliberately portable across any language model. Foundation Context is expressed in natural language any model can interpret. The Intelligence Layer is stored in standard formats: vector databases, structured documents, APIs that connect to any model. The Execution Layer uses patterns that transfer across providers.
The design principle is simple: treat the model as a replaceable processor and the context as the permanent operating system. Your context architecture should outlive any individual model by years. It is the accumulation of your organisational intelligence, and it is too valuable to lock inside any single provider’s ecosystem.
The Context Steward: who owns this?
Context engineering creates a new organisational capability that requires a named owner. Without one, context architectures degrade through natural entropy. Nobody’s responsibility means nobody’s priority.
In organisations under 50 people, the Context Steward is typically a responsibility added to an existing role: a Head of Operations, a Chief of Staff, or a technically-minded founder. In larger organisations, it may be a dedicated role.
The Context Steward owns three domains. Architecture ownership means maintaining the Context Constitution, managing the Intelligence Layer, and ensuring Execution templates stay current. Quality monitoring means tracking performance metrics and identifying where the architecture is underperforming. Cross-functional coordination means ensuring that changes in the business are reflected in the context architecture before the AI starts producing outputs based on stale information.
The Context Steward does not need to be deeply technical. They need to understand the business, understand what the AI needs to know, and have the organisational authority to ensure that knowledge flows into the context architecture in a timely fashion. The best Context Stewards are often the person everyone already goes to when they want to know “how things work around here.”
The 90-day Context Architecture Method sprint
The Context Architecture Method is designed for rapid deployment.
Days 1 to 14: Run the Context Audit. Interview five to ten key stakeholders. Harvest existing documentation. Analyse recent AI interactions. Output: Raw Knowledge Inventory and a scored assessment across six dimensions: Knowledge Accessibility, Identity Clarity, Memory Architecture, Compression Efficiency, Composition Sophistication, and Compounding Velocity.
Days 15 to 30: Curate and Compress. Sort the Knowledge Inventory into the three buckets. Write the Context Constitution. Compress all Always-On context to maximum density. Build or configure the retrieval pipeline. Output: Context Constitution, Knowledge Schema, Retrieval System.
Days 31 to 60: Compose and Deploy. Design Context Assembly Patterns for each major workflow. Build composition logic. Deploy with the new architecture. Run parallel testing. Measure baseline metrics.
Days 61 to 90: Compound and Optimise. Analyse 30 days of production data. Identify top failure modes. Mine successful interactions. Establish a weekly review cadence. Output: Optimised context architecture, Compounding playbook, Context Performance Dashboard.
Why this connects to the deeper work
The businesses that struggle most with context engineering are not the ones with the weakest technical teams. They are the ones with the weakest identity.
If you do not know who you are as an organisation, your values, your voice, your non-negotiable principles, no amount of technical sophistication will produce coherent AI outputs. The Foundation Layer requires foundational clarity. The Context Constitution is, in the end, just an articulation of who you are and what you stand for.
This is why the Being layer of the Absolutely Awesome Framework is not a philosophical luxury. It is the prerequisite for every layer above it, including, now, your AI’s ability to represent you in the world.
The companies that will thrive in the age of AI are not the ones with the most tokens. They are the ones with the most context. And context, at its deepest level, is just another word for knowing who you are, what you know, and what you are trying to do.
When you get that right, the technology takes care of itself.
The context moat: why this advantage compounds

Here is the strategic end state. Two competing businesses, both using the same frontier model.
Company A has no context architecture. Generic prompts, generic results. Every interaction starts from zero.
Company B invested 90 days in building a Context Architecture. Their AI systems know the company, its products, its customers, its voice, its standards, and its decision frameworks.
Both pay the same for the model. But Company B extracts 10x more value from every token spent. And because they are in the Compound phase, their advantage grows every week.
This is the context moat. It cannot be copied by switching to the same model. It can only be built through the deliberate, systematic work of capturing, curating, compressing, composing, and compounding institutional knowledge.
The Artificial Hivemind research proves this at scale: without distinctive context, every AI system converges on the same output. The only escape from the hivemind is your context. Your knowledge, your voice, your methodology, your principles. No competitor can replicate that simply by choosing the same model.
Where to go from here
If you are a solo founder or small team: Start with your Context Constitution. Write a 1,000-word document defining your voice, your values, your non-negotiables, and five examples of writing you consider excellent. Connect your existing knowledge base to your AI tools via retrieval. Build three task-specific context templates. Measure your one-shot success rate before and after.
If you are leading a growing business: Run the Context Audit across the six dimensions. Identify two or three high-impact AI workflows. Execute a 90-Day Context Sprint. Appoint a Context Steward.
If you are in an enterprise: Commission a formal Context Architecture assessment. Establish a context engineering team. Define the organisational Foundation Context. Build governance for federated context management using the “constitution and bylaws” model where the central Foundation Context is non-negotiable, and departmental contexts operate as bylaws within those guard rails.
The window for building a genuine context moat is open right now. The businesses that move in the next 12 months will have a compounding advantage that grows increasingly difficult to close.
The model is a commodity. The context is the company.
Frequently asked questions
What is the difference between prompt engineering and context engineering?
Prompt engineering focuses on how to phrase a request to get a better response. Context engineering focuses on the full system of information, identity, knowledge, and instructions that an AI needs to operate effectively. Prompt engineering is a writing skill. Context engineering is an architecture skill.
How long does it take to build a basic context architecture?
A solo founder can have a meaningful context architecture in place within two weeks. A small team can complete the foundation in 30 days. The 90-Day Context Sprint takes a business from ad-hoc AI usage to a production-grade context architecture with measurement in place.
Does context engineering work with any AI model?
Yes. The Context Architecture Method is deliberately model-agnostic. Because Foundation Context is expressed in natural language and the Intelligence Layer uses standard data formats, the architecture ports across providers. The goal is to treat models as replaceable processors and the context architecture as your permanent organisational operating system.
What is Context Entropy and how do I manage it?
Context Entropy is the natural decay of context quality over time as prices change, policies update, and knowledge becomes stale. You cannot prevent it, but you can manage it with Freshness Scoring: tagging every context element with a review date and automatically flagging overdue items for verification.
What is the single highest-ROI first step?
Write your Context Constitution. A 1,000 to 1,500-word document defining your AI’s voice, values, and non-negotiables. This is the highest-impact investment in your AI infrastructure. The improvement in output consistency from this single step is immediate and dramatic.
